Est-ce que le stockage Ceph Mars 400 prend en charge la reprise après sinistre?
Le stockage Ceph Mars 400 prend en charge la reprise après sinistre avec 2 protocoles de stockage.
1. Stockage en bloc - Miroir asynchrone pour RBD.
2. Stockage d'objets - Prise en charge active-active de RGW Multisite.
Les utilisateurs peuvent utiliser le gestionnaire UVS pour configurer la reprise après sinistre pour RBD et S3.
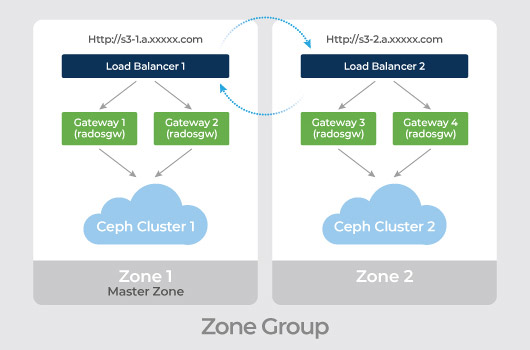
Le stockage Ceph Mars 400 peut utiliser RGW multi-site actif-actif pour différentes géolocalisations, offrant un cluster de stockage hautement disponible.
L'appliance Mars 400 ceph prend en charge l'installation multisite actif-actif pour rendre les données disponibles sur plusieurs emplacements différents.
Les utilisateurs peuvent utiliser le gestionnaire UVS sur Mars 400 pour exécuter :
● Créer la passerelle Rados pour le multisite - Principal.
● Créer la passerelle Rados pour le multisite - Secondaire.
● Définir le groupe de zones avec ces passerelles Rados multisite.
● Obtenir la clé d'accès utilisateur.
● Obtenir la clé secrète utilisateur.
● Promouvoir le site secondaire en tant que site principal en cas de défaillance du site principal.
Pour plus de détails, n'hésitez pas à contacter l'équipe Ambedded ou les partenaires Ambedded.

Grâce à la mise en miroir asynchrone Ceph RBD, le site secondaire peut sauvegarder les données du site principal pour éviter toute perte de données.
Pour le stockage en bloc, l'appliance Mars 400 ceph prend en charge la mise en miroir asynchrone RBD entre le site primaire (A) et le site secondaire (B).
● En cas de modification ou de nouveauté sur le site primaire (A), l'image et l'instantané RBD seront mis en miroir sur le site secondaire (B).
● Dans tous les cas, si les utilisateurs souhaitent restaurer une date antérieure, ils peuvent revenir à l'image correspondant à l'instantané spécifique.
● Si le site primaire (A) tombe en panne, le serveur client peut basculer ses connexions vers le site secondaire (B) pour continuer le service. Mars 400 peut également promouvoir le site secondaire (B) en tant que site primaire en cas de défaillance du site primaire d'origine (A).
● Lorsque le cluster A revient à la normale, les données peuvent être synchronisées vers le site A pour un retour en arrière.