
Alta disponibilidad y durabilidad de datos
El almacenamiento de objetos Ceph logra la disponibilidad de datos a través de la replicación y la codificación avanzada de borrado, donde los datos se combinan con información de paridad, se fragmentan y se distribuyen en el grupo de almacenamiento.
Cuando un dispositivo de almacenamiento falla, solo se necesitan un subconjunto de fragmentos para reparar los datos, no hay tiempo de reconstrucción ni rendimiento degradado, y los dispositivos de almacenamiento fallidos se pueden reemplazar cuando sea conveniente.
Ceph combina datos ampliamente distribuidos y tecnología de verificación continua de datos que valida los datos escritos en el medio, lo que le permite lograr una durabilidad de datos de 15 nueves.
Replicación de datos, codificación de borrado y verificación
Replicación de objetos
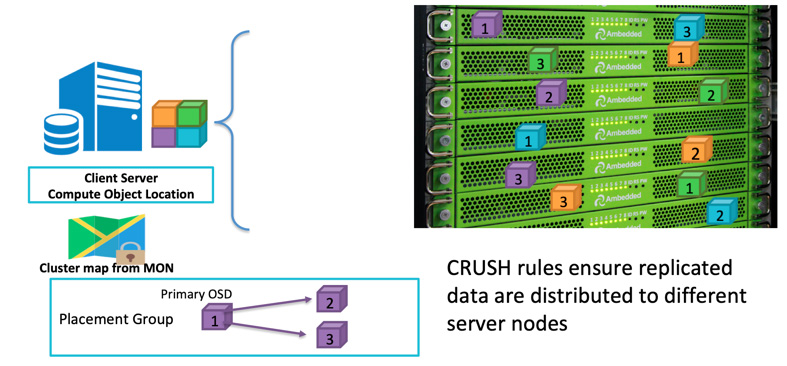
Cuando un cliente va a escribir datos, utiliza el ID del objeto y el nombre del grupo para calcular a qué OSD debe escribir. Después de que el cliente escribe datos en el OSD, el OSD copia los datos en uno o más OSD. Puede configurar tantas réplicas como desee para que los datos puedan sobrevivir en caso de que varios OSD fallen simultáneamente. La replicación es similar al RAID-1 de una matriz de discos pero permite más copias de datos. Porque a gran escala, una simple replicación RAID-1 puede que ya no cubra suficientemente el riesgo de fallos de hardware. El único inconveniente de almacenar más réplicas es el costo de almacenamiento.
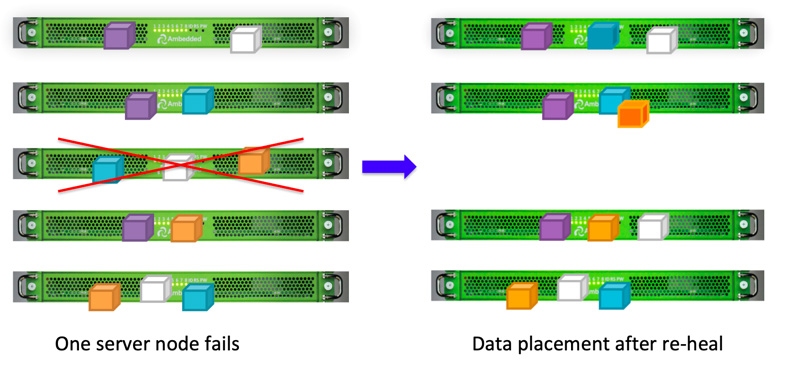
Los clientes de Ceph escriben datos aleatoriamente en los OSDs en función del algoritmo CRUSH.Si el disco OSD o el nodo fallan, Ceph puede volver a sanar los datos a partir de otras réplicas almacenadas en OSDs sanos.
Puede definir el dominio de fallo para hacer que Ceph almacene datos replicados en diferentes servidores, bastidores, salas o centros de datos para evitar la pérdida de datos debido a uno o más fallos de todo el dominio de fallo.Por ejemplo, si tienes 15 servidores de almacenamiento instalados en 5 racks (3 servidores en cada rack), puedes utilizar la réplica tres y el rack como dominio de fallos.La escritura de datos en el clúster ceph siempre tendrá tres copias almacenadas en tres de los cinco racks.Los datos pueden sobrevivir si fallan hasta 2 de los racks sin degradar el servicio al cliente.La regla CRUSH es la clave para que el almacenamiento Ceph tenga ningún punto único de fallo.
Codificación de borrado
La replicación ofrece el mejor rendimiento general, pero no es muy eficiente en el uso del espacio de almacenamiento.Especialmente si necesitas un mayor grado de redundancia.
Tener una alta disponibilidad de datos es la razón por la que en el pasado usamos RAID-5 o RAID-6 como alternativa a RAID-1.El RAID de paridad garantiza redundancia con mucho menos sobrecarga de almacenamiento a costa del rendimiento de almacenamiento (principalmente el rendimiento de escritura).Ceph utiliza codificación de borrado para lograr un resultado similar.Cuando la escala de su sistema de almacenamiento se vuelve grande, es posible que se sienta inseguro al permitir que solo uno o dos discos o dominios de falla fallen al mismo tiempo.El algoritmo de código de borrado le permite configurar un mayor nivel de redundancia pero con menos espacio de sobrecarga.
El codificado de borrado divide los datos originales en K fragmentos de datos y calcula los fragmentos de codificación M adicionales.Ceph puede recuperar los datos de un máximo de M dominios de falla que fallen en el ínterin.El total de K+M de fragmentos se almacena en los OSD, que se encuentran en diferentes dominios de fallos.

Limpieza
Como parte de mantener la consistencia y limpieza de los datos, los demonios OSD de Ceph pueden escanear objetos dentro de los grupos de colocación. Es decir, los demonios OSD de Ceph pueden comparar los metadatos del objeto en un grupo de colocación con sus réplicas en grupos de colocación almacenados en otros OSD. El proceso de limpieza (generalmente realizado a diario) detecta errores de programación o errores en el sistema de archivos. Los demonios OSD de Ceph también realizan un escaneo más profundo comparando los datos en los objetos bit a bit. La limpieza profunda (generalmente realizada semanalmente) encuentra sectores defectuosos en una unidad que no eran aparentes en una limpieza ligera.
Curación de datos
Debido al diseño de ubicación de datos de Ceph, los datos son reparados por todos los OSDs saludables. No se requiere un disco de repuesto para la re-sanación de datos. Esto puede hacer que el tiempo de re-sanación sea mucho más corto en comparación con el arreglo de discos, que tiene que reconstruir los datos perdidos en el disco de repuesto.
- Configurar mapa CRUSH y reglas