Almacenamiento distribuido
Puedes usar Ceph para construir un clúster de servidores para almacenar datos con alta disponibilidad. Las réplicas de datos o los fragmentos de código de borrado se almacenan de forma distribuida en dispositivos que pertenecen a diferentes dominios de fallos predefinidos. Ceph puede mantener su servicio de datos sin pérdida de datos cuando fallan múltiples dispositivos, nodos de servidor, racks o sitios al mismo tiempo.
Almacenamiento definido por software Ceph
Los clientes interactúan directamente con todos los dispositivos de almacenamiento para leer y escribir utilizando el algoritmo de almacenamiento distribuido CRUSH de Ceph. Debido a esto, se elimina el cuello de botella en el tradicional Host Bus Adaptor (HBA), que limita la escalabilidad del sistema de almacenamiento. Ceph puede escalar su capacidad de manera lineal con un rendimiento a escala de exabytes.
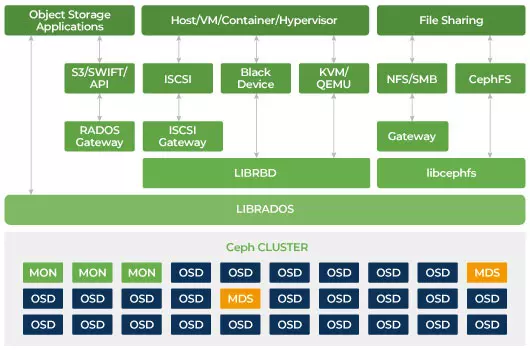
Ceph está diseñado para ser escalable y no tener un único punto de fallo. Monitor (MON), Object Storage Daemon (OSD) y Metadata Servers (MDS) son tres daemons clave (procesos de Linux) en el clúster de Ceph. Por lo general, un clúster de Ceph tendrá tres o más nodos de monitorización para redundancia. Los monitores mantienen una copia maestra de los mapas del clúster, lo que permite a los clientes de Ceph comunicarse directamente con OSD y MDS. Estos mapas son un estado crítico del clúster necesario para que los demonios de Ceph se coordinen entre sí. Los monitores también son responsables de gestionar la autenticación entre los demonios y los clientes. Los números impares de monitores mantienen el mapa del clúster utilizando un quórum. Este algoritmo evita el único punto de fallo en el monitor y garantiza que su consenso sea válido. OSD es el demonio de almacenamiento de objetos para Ceph. Almacena datos, maneja la replicación de datos, recuperación, reequilibrio y proporciona información de monitoreo a los Monitores de Ceph al verificar otros Demonios OSD para el latido del corazón. Cada servidor de almacenamiento ejecuta uno o varios demonios OSD, uno por dispositivo de almacenamiento. Por lo general, se requieren al menos 3 OSD para garantizar la redundancia y alta disponibilidad. El demonio MDS gestiona los metadatos relacionados con los archivos almacenados en el Sistema de Archivos Ceph y también coordina el acceso al clúster de almacenamiento compartido de Ceph. Puedes tener múltiples MDS activos para redundancia y equilibrar la carga de cada MDS. Solo necesitarás uno o más Servidores de Metadatos (MDS) cuando quieras utilizar el sistema de archivos compartido.
Ceph es almacenamiento escalable
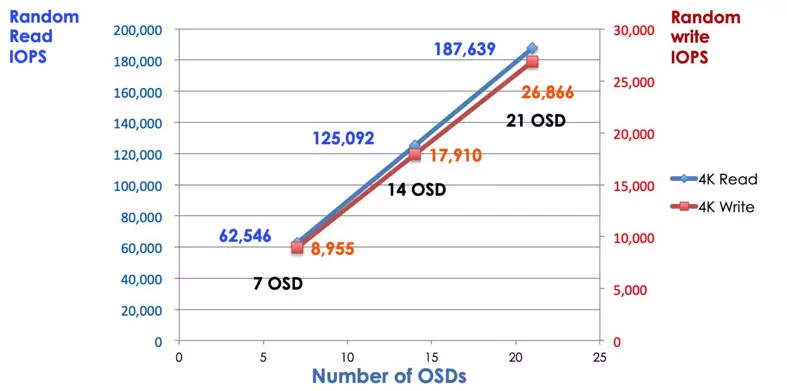
En un sistema de almacenamiento tradicional, los clientes se comunican con un componente centralizado (por ejemplo, un adaptador de bus de host o una puerta de enlace), que es un único punto de entrada a un subsistema complejo. El controlador centralizado impone un límite tanto al rendimiento como a la escalabilidad, además de introducir un único punto de fallo. Si el componente centralizado se cae, todo el sistema también se cae. Los clientes de Ceph obtienen el mapa del clúster más reciente de los monitores y utilizan el algoritmo CRUSH para calcular qué OSD en el clúster. Este algoritmo permite a los clientes interactuar directamente con Ceph OSD sin pasar por un controlador centralizado. El algoritmo CRUSH elimina la ruta única, lo cual causa una limitación de escalabilidad. El clúster de OSD de Ceph proporciona a los clientes un pool de almacenamiento compartido. Cuando necesites más capacidad o rendimiento, puedes agregar nuevos OSD para ampliar el grupo. El rendimiento de un clúster de Ceph es proporcionalmente lineal al número de OSD. La siguiente imagen muestra el aumento de las IOPS de lectura/escritura si aumentamos el número de OSD.
El arreglo de discos tradicional utiliza el controlador RAID para proteger los datos de fallos en los discos. La capacidad de un disco duro era de aproximadamente 20MB cuando se inventó la tecnología RAID. Hoy en día, la capacidad del disco es tan grande como 16TB. El tiempo para reconstruir un disco fallido en el grupo RAID puede llevar una semana. Mientras el controlador RAID está reconstruyendo la unidad fallida, existe la posibilidad de que un segundo disco pueda fallar simultáneamente. Si la reconstrucción lleva más tiempo, la probabilidad de perder datos es mayor.
Ceph recupera los datos perdidos en el disco fallido mediante todos los demás discos sanos en el clúster. Ceph solo reconstruirá y sanará los datos almacenados en el disco fallido. Si hay más discos sanos, el tiempo de recuperación será más corto.
- Configurar mapa CRUSH y regla de Ceph