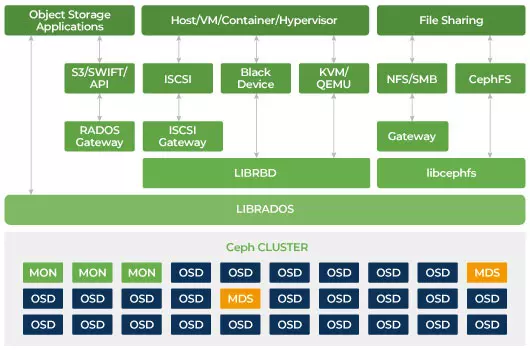
Distributed Storage
You can use Ceph to build a server cluster for storing data in high availability. Data replications or erasure code chunks are distributively stored in devices which belong to different pre-defined failure domain. Ceph can maintain its data service without data lost when multiple devices, server nodes, racks, or sites fail at a time.
Ceph Software-Defined Storage
Clients interact directly with all storage devices to read and write utilizing Ceph's distributed storage algorithm CRUSH. Because of this, it eliminates the bottleneck on the traditional Host Bus Adaptor (HBA), which limits the scalability of the storage system. Ceph can scale out its capacity linearly with performance to the exabyte scale
Ceph is designed to be scalable and to have no single point of failure. Monitor (MON), Object Storage Daemon (OSD), and Metadata Servers (MDS) are three key daemons (Linux process) in the Ceph cluster. Usually, A Ceph cluster will have three or more monitor nodes for redundancy. Monitors maintain a master copy of the cluster maps, which allow Ceph clients to communicate with OSD and MDS directly. These maps are critical cluster state required for Ceph daemons to coordinate with each other. Monitors are also responsible for managing authentication between daemons and clients. Odd numbers of monitors maintain the cluster map using a quorum. This algorithm avoids the single point of failure on the monitor and guarantees that their consensus is valid. OSD is the object storage daemon for the Ceph. It stores data, handles data replication, recovery, rebalancing, and provides some monitoring information to Ceph Monitors by checking other OSD Daemons for hart beat. Every storage server runs one or multiple OSD daemons, one per storage device. At least 3 OSDs usually are required for redundancy and high availability. The MDS daemon manages metadata related to files stored on the Ceph File System and also coordinates access to the shared Ceph Storage Cluster. You can have multiple active MDS for redundancy and balance the load of each MDS. You will need one or more Metadata Servers (MDS) only when you want to use the shared file system.
Ceph Is Scalable Storage
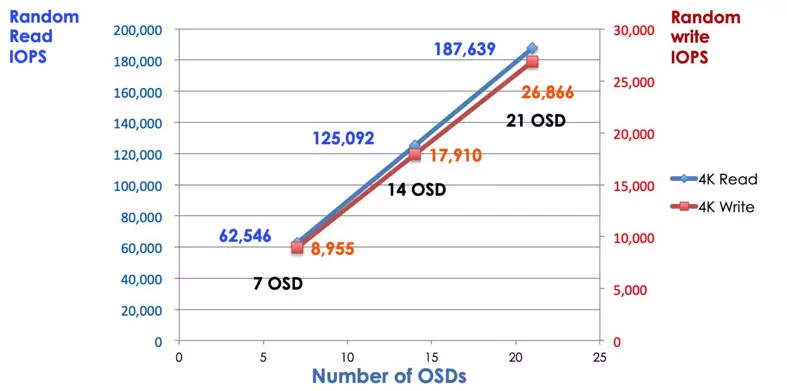
In a traditional storage system, clients talk to a centralized component (e.g., host bus adaptor or gateway), which is a single point of entry to a complex subsystem. The centralized controller imposes a limit to both performance and scalability as well as introducing a single point of failure. If the centralized component goes down, the whole system goes down, too.Ceph clients get the latest cluster map from monitors and use the CRUSH algorithm to calculate which OSD in the cluster. This algorithm enables clients to interact with Ceph OSD directly without going through a centralized controller. CRUSH algorithm eliminates the single path, which causes the limitation of scalability. Ceph OSD cluster provides clients a shared storage pool. When you need more capacity or performance, you can add new OSD to scale out the pool. The performance of a Ceph cluster is linearly proportional to the number of OSD. The following picture shows the read/write IOPS increases if we increase the number of OSD.
Traditional disk array uses the RAID controller to protect data from disk failure. The capacity of a hard disk drive was about 20MB when the RAID technology was invented. Today the disk capacity is as large as 16TB. The time to rebuild a failed disk in the RAID group may take a week. While the RAID controller is rebuilding the failed drive, there is a chance of a second disk could fail concurrently. If the rebuild takes a longer time, the probability of losing data is higher.
Ceph recovers the data lost in the failed disk by all other healthy drives in the cluster. Ceph will only rebuild/heal the data stored in the failed drive. If there is more healthy disks, the recovery time will be shorter.
- Config Ceph CRUSH Map & Rule