Распределенное хранилище
Вы можете использовать Ceph для создания кластера серверов для хранения данных с высокой доступностью. Репликации данных или кодирование частей осуществляется распределенно на устройствах, принадлежащих различным предопределенным областям отказа. Ceph может поддерживать свою службу данных без потери данных, когда одновременно отказывают несколько устройств, узлов сервера, стоек или сайтов.
Хранилище Ceph, определенное программным обеспечением
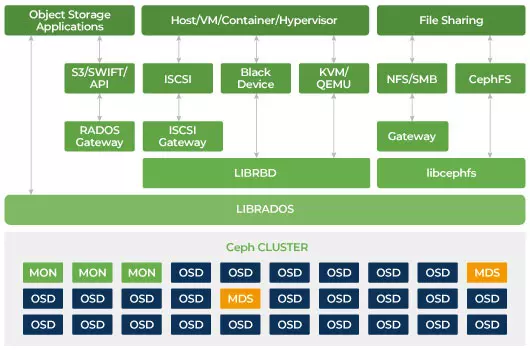
Клиенты взаимодействуют напрямую со всеми устройствами хранения для чтения и записи с использованием распределенного алгоритма хранения CRUSH в Ceph. Благодаря этому устраняется узкое место на традиционном адаптере шины хоста (HBA), которое ограничивает масштабируемость системы хранения. Ceph может линейно масштабировать свою емкость с производительностью до экзабайтного масштаба.
Ceph разработан для масштабирования и отсутствия единой точки отказа. Монитор (MON), демон объектного хранилища (OSD) и серверы метаданных (MDS) - это три ключевых демона (процесса Linux) в кластере Ceph. Обычно в кластере Ceph будет три или более узлов монитора для обеспечения отказоустойчивости. Мониторы поддерживают основную копию карт кластера, которые позволяют клиентам Ceph взаимодействовать напрямую с OSD и MDS. Эти карты являются критическим состоянием кластера, необходимым для согласования работы демонов Ceph между собой. Мониторы также отвечают за управление аутентификацией между демонами и клиентами. Нечетные номера мониторов поддерживают карту кластера с помощью кворума. Этот алгоритм избегает единой точки отказа на мониторе и гарантирует, что их согласие является действительным. OSD - это демон объектного хранилища для Ceph. Он хранит данные, обрабатывает их репликацию, восстановление, балансировку и предоставляет некоторую информацию о мониторинге Ceph Monitors, проверяя другие OSD-демоны на наличие сигнала. Каждый сервер хранения запускает один или несколько демонов OSD, по одному на каждое устройство хранения. Как минимум, обычно требуется 3 OSD для обеспечения избыточности и высокой доступности. Демон MDS управляет метаданными, связанными с файлами, хранящимися в Ceph File System, а также координирует доступ к общему хранилищу Ceph Storage Cluster. У вас может быть несколько активных MDS для обеспечения надежности и балансировки нагрузки каждого MDS. Вам понадобится один или несколько серверов метаданных (MDS) только в том случае, если вы хотите использовать общую файловую систему.
Ceph - масштабируемое хранилище
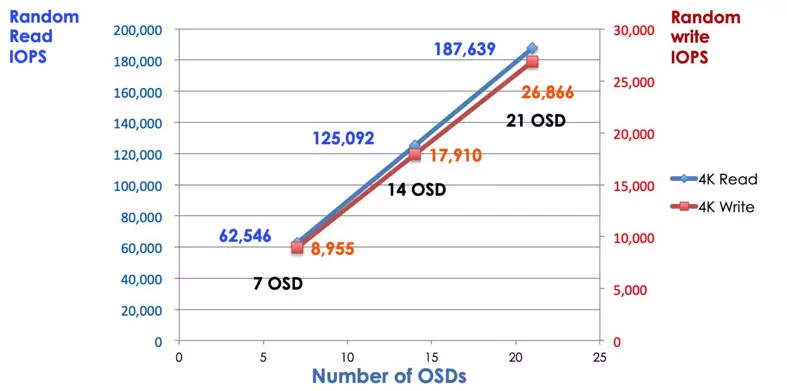
В традиционной системе хранения клиенты общаются с централизованным компонентом (например, адаптером шины хоста или шлюзом), который является единой точкой входа в сложную подсистему. Централизованный контроллер накладывает ограничения на производительность и масштабируемость, а также создает единую точку отказа. Если централизованный компонент выходит из строя, вся система также выходит из строя. Клиенты Ceph получают последнюю карту кластера от мониторов и используют алгоритм CRUSH для расчета, какой OSD в кластере. Этот алгоритм позволяет клиентам взаимодействовать с Ceph OSD напрямую, без прохождения через централизованный контроллер. Алгоритм CRUSH устраняет единственный путь, что вызывает ограничение масштабируемости. Кластер Ceph OSD предоставляет клиентам общий пул хранения. Когда вам нужна большая емкость или производительность, вы можете добавить новый OSD для масштабирования пула. Производительность кластера Ceph пропорциональна количеству OSD. На следующей картинке показано увеличение операций ввода-вывода чтения/записи при увеличении количества OSD.
Традиционный дисковый массив использует контроллер RAID для защиты данных от сбоев дисков. Емкость жесткого диска составляла около 20 МБ, когда была изобретена технология RAID. Сегодня объем диска составляет целых 16 ТБ. Время восстановления отказавшего диска в группе RAID может занять неделю. Во время восстановления отказавшего диска контроллером RAID существует вероятность одновременного отказа второго диска. Если восстановление занимает больше времени, вероятность потери данных увеличивается.
Ceph восстанавливает потерянные данные на неисправном диске с помощью всех остальных здоровых дисков в кластере. Ceph будет восстанавливать только данные, хранящиеся на неисправном диске. Если есть больше здоровых дисков, время восстановления будет короче.
- Настроить карту и правило CRUSH Ceph